
How three simple agreements improve flow significantly
Super Powerful! How "Full Kitting" Will Speed Up Your Cross-Team Projects
Delivering projects depending on multiple teams can be painful and slow, leading to an awful lot of coordination — but help is just around the corner. Make three decisions to let your projects flow.
tl;dr: Contemporary applications of the Theory of Constraints in the domain of knowledge work and agile product development do not suffice the needs of team-based organizations in which no single project is the same. This blog post closes a conceptual gap in applying the still relevant TOC to a modern, non-linear project world with ever-changing multi-team dependencies being the norm. Simulations make the effects of policy changes visible and guide a path to the parameters Global Per Team WIP limit, Dependent Project WIP limit, and Full Kitting. All three support a smooth flow of project work — resulting in increased throughput and project speed. This blog post aims at being practical and offers decisions to make and actions to take. And no, I’m not writing about any kind of ‘scaling framework’ — all of them suck.
Believe it or not but adjust just three simple parameters right, and you can dramatically speed up your multi-team projects— and I mean dramatically. How dramatically? 10%? 20% What about 90%? What if I tell you that it was possible to adjust a multi-team project setup to drop project durations from more than 1.000 workdays per project below 100? Impossible? Well, now that I have your attention, let me show you step by step what you can do to pull this miracle off.


Applying the Theory of Constraints in a non-linear world
I've been writing on improving flow in organizations for quite some time now. I've shown in practical detail how the timing when to start a project and the right amount of projects created influences project durations, the total throughput, and the profitability of an organization. If you haven't read my two recent blog posts on that topic, already I recommend reading those two first. This blog post builds upon the line of thought established in those other posts having catchy titles like "Predictably Speed up Your Product Delivery" and "Starting late — The Superior Scheduling Approach".
Although I've already laid out some very effective practices in the blog posts mentioned above, I have to admit that I've built those practices on a simplistic mental model that needed further refinement to be applicable in the realm of modern product development. I received some constructive critique on my reasoning, and I'm grateful for that since it motivated me to update and improve my previous thinking.
In my previous blog posts, I reasoned that every project and work item runs relatively linearly through an organization or a team — from idea to the preparation to the actual delivery. That sounds quite reasonable from a conceptual point of view; however, the practice is more nuanced. While being more or less applicable on a team level — assuming that some steps may be skipped now and then if not needed — on an organizational level, this mental model of a 'workflow' is — I have to admit — somewhat limited in applicability.

I've been talking to some organizations since I first published my posts above, and I recognized that only some of those organizations followed a linear 'project process' close to my conceptual perspective of project delivery. Only organizations that treat their formal organizational structure as the value creation structure tend to develop those 'waterfall-ish' workflows for their project delivery. For instance, the sales department may come up with a project when talking to a client and, with some intermediate steps pushing the project idea onto the IT department to deliver the value of the project to the client. Often those projects are centrally managed to apply some sort of portfolio project management.
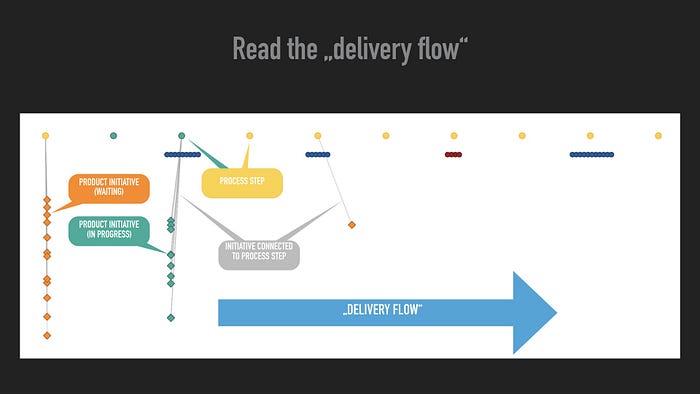
There is no doubt about the feasibility and the high effectiveness of applying the production-like Theory of Constraints (TOC), including Drum-Buffer-Rope, Deferred Commitment, and Pull in a more or less stable linear workflow organizational setting. I've shown that by applying those principles, a company can deliver projects almost 18 times faster than the competition, unaware of the power of TOC.
A different setting needs different practices
But what about organizations that have established a team-oriented approach? Many tech companies, for instance, have built an organizational structure in which teams' own' products or — more commonly — parts of the product leading to a non-linear flow of work through the organization. Often in those organizations, projects require many teams to collaborate simultaneously or in sequence to finish a project. This situation is often referred to as 'dependencies' that may result out of architectural interconnections, the need to keep functionality or the 'look and feel' in sync over several platforms (e.g., web and app), or out of the need to keep everyone informed if some technical pattern changes. Whatever the reasons, dependencies in value creation flows exist despite best efforts in the last couple of years. This understanding leads to a different mental model of a 'flow of work' for projects in those team-based organizations.
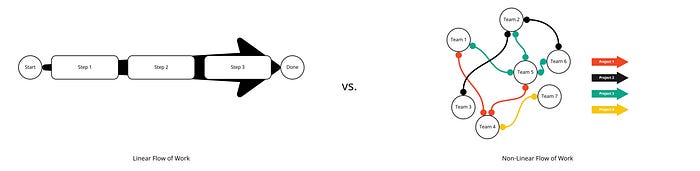
While the practices mentioned in the blog posts on speed and predictability remain applicable to project and work environments with a more linear flow of work, they are less useful to non-linear workflow environments. This blog post closes the conceptual gap and consistently applies the presented principles to a team-based value creation structure. The results are astonishing!
How to optimize for speed and throughput in a non-linear project flow?
Team-based projects in 'modern' tech companies share characteristics that are relevant when it comes to optimizing for delivery speed and throughput:
- Teams, not functions, deliver value to customers
- The teams that are involved may vary from project to project
- The degree of involvement for each team may vary from project to project
- The effort that each team spends on a project may not be (precisely) known before the project is already running
- Some teams may be involved more often in multi-team projects than other teams
- Every team may initiate projects in the organization — often involving other teams without explicit consent
- The total effort of a project may vary drastically from project to project
Acknowledging those circumstances, it seems reasonable to assume that other practices need to be in place than for more linear project settings if we want to improve flow drastically. Agreed, let's change the practices but not the principles. What principles do we want to keep applying?
- We aim for a smooth flow of work through the organization, which means to get the moment of starting work right. Starting too soon leads to multitasking and thus to all sorts of negative consequences.
- Having teams waiting for work within a project is desirable, and having a project waiting for the team's attention is not.
- Slack Time is mandatory for teams to remain responsive.
- Teams need the authority to 'pull' work as soon as the attention and capacity to start new work is available — saying "no, not now" to new work — in contrast to work being pushed onto them by 'forces' outside the team. The difference between pull and push is massive and cannot be understated.
- Aiming for a smooth flow of work and embracing 'pull' needs work in process limits (WIP limit). Since the importance of WIP limits is covered extensively, I'm not going to dive into those.
Starting work too early is the root of all evil. *
How do we incorporate those principles in a work environment where non-linear project workflows are the norm?
Three parameters to let work flow
I often find it hard to make the effects of the parameters described below immediately visible in a natural working environment. You may agree that it's not very practical to 'experiment' with many project-loaded teams on how an ideal project-delivery setting may look. I've created a tiny simulation of a team-based organization working on a continuous flow of new projects to overcome this obstacle. A Simulation makes it easy to play around with some parameters, immediately witnessing the effects on project speed and total project throughput. Don't you worry; the simulation is based on real-world cases and encompasses a certain degree of randomness to mimic the real world closely (if you want to read about the simulation in detail, you find a description at the end of this text).
We simulate four relatively small organizations consisting of five teams each to keep it simple. Each of these teams can deliver projects of value independently but occasionally needs collaboration with other teams. Which teams will be involved in finishing a project and to which extend is randomly determined by the simulation. New projects are created randomly from time to time. All the scenarios compared below simulate a 2.000 workday period.

We take a look at three parameters that massively affect the speed of project execution and thus the project throughput of an organization:
- The 'global per team WIP limit' (on how many projects a team works simultaneously?) This parameter includes projects with a multi-team dependency and projects that a single team can finish alone.
- The per team WIP limit for projects that have a multi-team dependency (how many projects with a dependency of more than one team shall be processed per team simultaneously)
- Do we enforce 'Full Kitting'?
If Full Kitting is enforced, projects may only start if all the teams knowingly needed to finish this project start simultaneously.
Don't worry; I will explain "Full Kitting" more in-depth further down in the text.
Let's go step by step, checking the effect of each parameter on median project duration, overall project throughput, and the reliability of the delivery organization. To make the simulation results more reliable, each setup has been run several times in a Monte Carlo Simulation approach leading to median values that we can compare.
Company A — (almost) no limits
The Setup in Company A is straightforward. All five teams can start new projects as soon as they appear, and teams can run up to 10 projects per team in parallel. The teams wouldn't call that a WIP limit; they call it "overload", making starting any new project impossible. The practice of Full Kitting is not applied. I assume something like this 'non-regulated project setup' is common practice in most companies out there.

If you take a closer look at the simulation below, you may see that the flow of projects running 'through the delivery pipe' is clogged after some time. While the first dependent projects seem to run smoothly, the newly arriving projects at some point get overwhelming. The limit of 10 parallel projects per team starts to pay its toll, and projects almost stop making progress. Some projects even start running downwards, meaning that their progress is negative — which in practice is quite common, thinking of rework and increasing scope due to long project Flow Times.
All five teams together deliver in a 2.000 workday period 26 projects. The project Flow Time* (the time from starting a project to finishing a project) is 1.154 workdays. Let's keep this as our benchmark. Looking at the Flow Time Scatterplot of Company A, we recognize that the delivery process is unpredictable with increasing Flow Times over time.
*The median Flow Time is derived from the 85th percentile of all the project Flow Times in the simulation to be more robust towards outliers. Find more about the details of the simulation below.



Company B — Global per team WIP limit of 5
Company B knows the power of WIP limits. All five teams in the organization agreed to never work on more than five projects per team, including projects that can be delivered independently by a single team and projects that have specific dependencies between the teams. Each team can immediately start an upcoming project if the WIP limit is not violated and full Kitting is not applied.

Observing the flow of projects through Company B, we recognize a more smooth project flow with fewer clogs as we've seen in Company A. Still, many dependencies between teams need to be tackled, and it still looks painfully slow.
The five teams deliver 32 projects in 2.000 workdays, and a project takes a median of 621 workdays to be finished (Flow Time). Quite impressive compared to Company A's 1.154! Since we know how important it is for a company to be fast these days, finishing projects 50% faster than your competitor (Company A) is quite something due to a simple per team WIP limit of five projects.



Company C — Global per Team WIP limit of 2
If bringing the global per team WIP limit down from 10 to 5 is beneficial to throughput and Flow Times, what about cutting the per team WIP limit in half once again? That's what Company C thought after recognizing Company B's results published publicly. All teams in Company C agree that not having more than two projects in parallel is the way to go. Still, Full Kitting is not applied.

Company C seems to be onto something. The projects start to flow, having only minor disruptions now and then. How do the results of the teams' play out?
The operating agreements in Company C result in a median Flow Time of 207 workdays per project with reduced variability and a throughput of 72 projects in the 2.000 workday period. Hey, that's even more impressive than Company B! Contrasting Company A, Company C is more than five times faster and delivers almost three times more projects, 'only' by increasing the focus with not having more than two projects per team in the making.
“Our focus is…blah!” Baloney! Focus is not something you HAVE. Not a thing you can acquire. Focus is something you DO: “We focus…” or “I focus…”. Focusing is an activity that requires concentration and also effort. * Inspired by Greg McKeown
By evaluating their Flow Time Scatter Plot (Run Chart), the teams also recognize that the projects delivered independently in each team are consistently faster than the projects with dependencies. That is interesting since the independent projects are comparable in size and scope to those with dependencies.



Company D — Maximum focus with a per team WIP limit of 1
The teams in Company D have experienced that creating a razor-sharp focus gives them the best flow experience leading to high productivity. That's why they agree to have a global per team WIP limit of only one project at a time, regardless of whether it is independent or dependent.

Observing the flow of projects through the organization clarifies that a razor-sharp focus leads to many projects waiting to start (yellow squares). I feel my impatience rise by just looking at this image below. But is it worthwhile to let all those great project ideas wait? On the upside, one can tell that those projects in process (green squares) move pretty quickly and without significant disruptions.

Company D reliably delivers projects 11 times faster than Company A — 102 workdays median project Flow Time compared to 1.154 workdays— resulting in 82 projects delivered in 2.000 workdays although with quite some variability in the different Monte Carlo runs (from 71 up to 130 projects). Just imagine those Flow Time differences from a customer's perspective. We are discussing the difference between finishing two projects equal in total effort in more than 4.5 years or less than five months. The delivery reliability of Company D's teams is good as well. With just some exceptions, the Flow Time per project seems reasonably predictable.



Can that be improved? Is a Work in Process Limit of one the best we can do to improve flow? Well, there is more; we can come way closer to One-Piece Flow than just having a WIP limit of one.
Full Kitting: More than icing on the cake
While the numbers seem impressive, Company C and Company D are hungry for more. They want to be the fastest and deliver the most — of course, without neglecting quality and with the highest employee satisfaction.

They both stumble upon a practice called 'Full Kitting' originating in the physical world of production and assembly. The idea with Full Kitting is that a work center (men:women, methods, measures) shall only start to work on a component or a product if all the needed parts to finish the assembly or production in one fell swoop are available. Full Kitting was introduced to avoid unfinished components piling up due to missing parts leading to poor production lead times and high amounts of incomplete goods inventory, which resulted in elevated amounts of fixed capital having severe consequences on companies' profitability.
In production and assembly, it became common to define 'Kits' that are composed out of all the parts needed to finish the work of a specific work center. The term Full Kitting describes the process of entirely composing those 'Kits' before they enter a work center. I got introduced to Full Kitting by Steve Tendon — Thank you, Steve!
“We discovered the value of Full-Kitting as a means to ensure that work flows in an uninterrupted manner through the system. The activity happens “upstream” — before work actually enters the design, implementation and delivery phases.” Steve Tendon *
Companies C and D recognize that this physical world practice is highly applicable to their digital knowledge work. When needed, not having the right capabilities in place is a widespread phenomenon in their project environment. The teams in both Companies come up with a practice to only start a new project if every team that is knowingly involved in that project is available and can contribute their full attention and capacity to the work on that project. If only one team is still engaged in working on another project, all the other project teams remain to wait until every team signals being ready — resulting in Slack Time for every team but one. For all the TOC enthusiasts out there, this practice makes 'constraint teams' immediately visible without the need for a project plan.
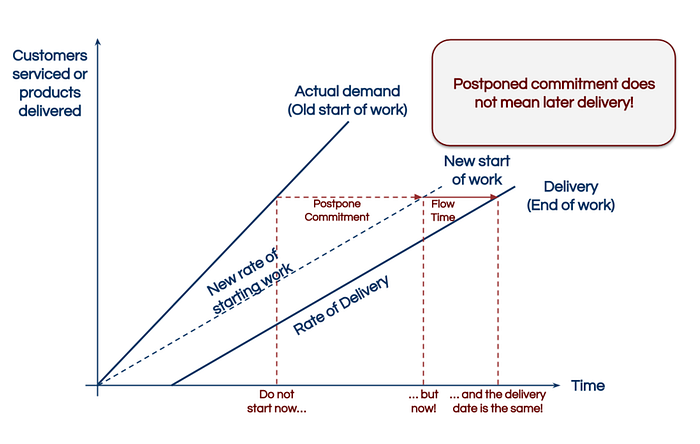
If we think about it, it becomes evident that having a simultaneous project start for all the teams involved reduces the Flow Time of a project without changing the project's content — we start the stopwatch later. And having everyone's full attention and dedication involved in the project work reduces waiting time in the project, reduces rework due to faster communication, and massively increases the feeling of self-efficacy for the people involved — allowing us to stop our stopwatch earlier.
Company C's second attempt — Global per team WIP limit 2 and Full Kitting
In its advanced second attempt, the teams in Company C agree to only work on one multi-team project at a time. Moreover, they agree that it's allowed to have a second team internal project running while simultaneously working on the multi-team project. When a dependent project waits, starting is only permitted if all the teams involved have their full attention and capacity available for this particular project. That leads to an explicit and simultaneous 'pull signal' from all teams involved — cross-team projects have to be 'fully kitted'.
Full and uninterrupted attention is the scarce resource not the peoples time.

Observing the second attempt of Company C's teams, we may recognize many projects waiting — especially those that have a dependency. The commitment to start a project is deferred. While the dependent projects remain in the queue, the teams dedicate their attention to the in-team projects, which in return seem to finish rather quickly.
Compared to Company C's previous work mode of just having a global per team WIP limit of 2, the median Flow Times dropped significantly when introducing Full Kitting. From being 207 workdays per project down to 77 workdays. Considering that we talk about a simple policy change with not a single Euro spent and no new colleagues hired, this result is quite something. In 2.000 workdays, Company C's teams now deliver astonishing 184 projects coming from 72 previously. The Flow Time Scatterplot shows impressively how the reliability of Company C increased with their Full Kitting approach.



If we take a closer look at the Flow Time Scatterplot, we can see that the increased project throughput stems from the increase of finished non-dependent projects that have been worked on mainly while waiting for busy teams to start working on projects with dependencies.
Company D's second attempt — Global per team WIP limit 1 and Full Kitting
Since Company D is experienced with strict per team project WIP limits, they add the Full Kitting practice, hoping to outperform Company C.

Since the teams in Company D agreed on strictly limiting work in process to one per team while consistently applying Full Kitting before a project starts, we witness a lot of projects waiting for the teams' attention (yellow squares). We also see that single in-team projects may 'block' a multi-team project from starting. But is it worth it?
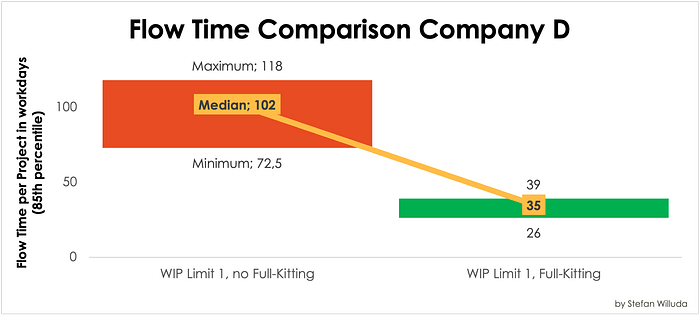
Coming from a median project duration of 102 workdays, Company D's teams now achieve incredible 39 workdays — which is just 40% of the previous Flow Time! From finishing 82 projects in a 2.000 workday period, they now finish 141 projects. And boy, are these teams reliable (see the Scatterplot)!



So is it worth it? Yes and no. Undoubtedly, having the fastest teams in the market is something — speed matters! Also, having the most reliable teams will create trust within the organization and with clients.
“Time orientation is a prerequisite for networking. Without reliability, networking is an illusion.” Ernst Weichselbaum *
One can argue that Company C's teams' speed and reliability are sufficient and that getting 30% more projects done than Company D means a lot to the customers. No doubt about that. However, this simulation only compares project delivery. While the simulation indicates that teams are sitting idle, in practice, those teams most probably would use their 'Slack Time' to work on something of value without considering this a project. So if we are looking at speed and reliability, Company D's second attempt is superior. If we believe project throughput is more valuable, Company C's approach to split the teams' attention is the way to go.
Let the results sink in — it's just a policy change
Without changing the organizational structure, without adding a single team, not even a single new employee, without spending a single Euro, and without working any longer or harder, the difference between Company A and Company D in its Full Kitting setup is a crazy 30 times speed difference. Company C finished seven times as many projects as Company A, although the projects are comparable in size (effort needed, number of teams involved). The companies are equal in capacity (number of teams, team's capacity). Moreover, Company D has a lot of excess capacity (Slack Time), resulting in less stress, better product quality, and more innovation.
As I've written before, Company D and Company C just alter three simple parameters to let the work flow. The teams agree on:
- not having more than one project (two projects for Company C respectively) per team at a time
- not having more than one multi-team project running per team
- enforce Full Kitting for every project before starting
Company A does nothing like that and seems overwhelmed by the flood of projects that float through its teams.
“If you want flow, stop the flooding.” Sally Elatta *


I'm not sure about you, but I can almost sense the pressure, stress, and busyness that the teams in Company A (picture on the left) may feel. Whenever I show those simulations to my clients, they feel this too. Just try to comprehend what the following Flow Time Scatterplots show and how this would translate to your business.


Try to imagine how almost chaotic it must feel to have projects finish almost randomly or with ever-growing project durations.
“Your process is unpredictable. What you may not realize, though, is that you are the one responsible for making it that way.” Daniel Vacanty *
The surprising effect of Full Kitting
We see the surprising effect of the Full Kitting practice when looking at Company D's first and second attempts in comparison. Just by adding the policy of Full Kitting before starting a project cuts the project Flow Times to one-third, making the already fastest Company even faster.
Too good to be true?
Usually, when I present this train of thought to people, they immediately challenge the validity of those numbers. It sounds downright unimaginable that teams can either deliver the same project in more than 1.000 workdays or 35 workdays. Also, the comparability of those four companies gets challenged quickly. No company is like another; teams cannot be compared, nor can projects. I agree with that critique. As I've written before, it's close to impossible to run a bulletproof A/B testing scenario in the real world. However, that's the beauty of this simulation. I can tell without a doubt that Company A and Company D are comparable because they are the same company. Only the parameters mentioned above— global per team WIP limit, the per-team WIP limit for dependent projects, and Full Kitting — have been changed, leading to those massive differences in performance.
But can those simulation results be applied to existing organizations? Yes! With a grain of salt. I've witnessed firsthand that projects running for more than two years involving almost a dozen teams have finished in less than four months after changing the policies on when and how to start those projects. The same teams were involved, and the project's scope has not been changed after this 'reset' (starting from scratch again). So with all confidence, I can say that the simulation results have many practical implications. The grain of salt comes from companies not being machines. That is a good thing. Companies are capable of reacting to surprises. But that also leads to a not-machine-like adoption of the practices mentioned here. Sometimes it can be challenging for a team to accept having 'Slack Time', resulting in prematurely starting a project. Sometimes work gets pushed onto a team (maybe by stakeholders or by formal management), although the agreement strictly tells 'a clear pull-signal is required'. I wrote a text on the human side of the Theory of Constraints some time ago. Those and similar inconsistencies degrade the simulated effects to some extent when applied in practice, but they don't eradicate them.
Planning is not an option
Most of the multi-project frameworks out there are well aware of the troubles of managing projects in this complex environment. Practices in those frameworks usually try to make all the dependencies for all the projects in the portfolio visible and then try to plan out a roadmap respecting the dependencies. You might have noticed that the teams in the companies in this blog post don't plan, don't estimate the duration of a project, and don't build roadmaps.
They don't do that because this practice does not add any value to forecasting or self-improvement. That's why improving the planning process is not included in my suggested parameters companies can adjust to improve flow. As long as we plan roadmaps, we fall for the fallacy that we have to know and reasonably can know the factors for flow upfront (effort needed, capacity available, priorities in the future, and so on). But we can't, we don’t need to, and we shouldn't try any longer.
“In practice, Full-Kitting replaces conventional detailed planning entirely, but it is not the same thing.” Steve Tendon *
As I've laid out, there are simpler and more powerful parameters to adjust the setting for flow and speed than fiddling around with the planning process. All these can be introduced in a collective effort built on a common knowledge that starting late is best for delivering fast.
Practical application — an inspiration, not a best practice
Honestly, it's pretty simple to bring to life the practices described above. It's simple but not easy. In detail, I've shown the dilemma holding us back from improving flow in a knowledge work environment. In short, we would like to be super responsive, having a high throughput while keeping the costs low. Since many organizations don't understand the implications of that dilemma for project execution in a knowledge work environment, bothersome behaviors like planning, roadmaps, or fixed date project schedules emerge.

Creating a shared understanding of what problems need to be fixed to improve flow is — from my experience — the most challenging part of adopting the practices above. Read here how it can be done. Without a shared understanding of the problems and their root causes, coming up with solutions that people will commit to is impossible.
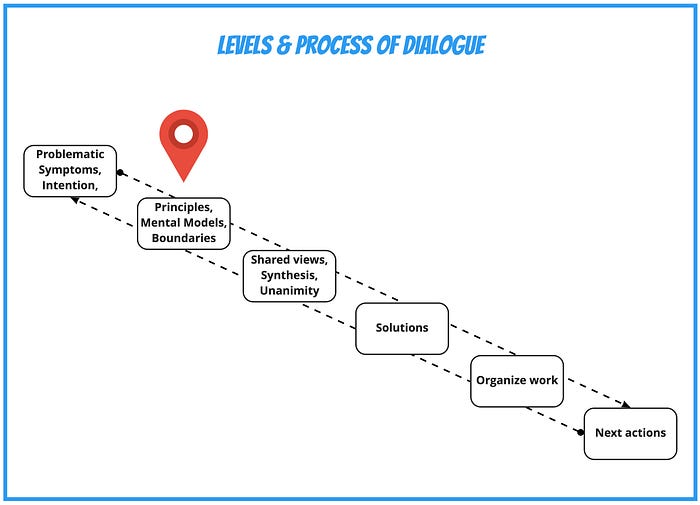
Working on a shared understanding can be challenging. What I found most helpful is to work with differentiation, and it may be easier to find common ground when the contradictions are evident.


You may also want to show how aiming for an early starting time leads to a different set of work principles than seeking a smooth flow. If you compare the following contradictory pairs of principles, you might immediately recognize how vastly different the translation outcomes into practices will be.

As soon as the practical implications of those principles are commonly understood and as soon as it's agreed that aiming for smooth flow is preferable for many reasons, practices can be developed. Some of them may be the following.
It needs some practice to create a stable flow of work. Moreover, it requires constant refinement and reflection on the practices in place. Do they comply with the underlying principles? Do people know how to apply the practices seamlessly? Do conflicts or tensions emerge that need attention? As I've written before, an organization is not a machine, and stability is an illusion. Even having the practices in place and the parameters described above adjusted right once does not mean you don't need to 'inspect and adapt'.
Underlying assumptions
The presented suggestions are built upon assumptions, and I want to make those explicit to give a practical application within your organization a chance of success. If you try to apply the practices without having the same context and boundary conditions, the practices will most certainly fail you. I make the following assumptions:
- The companies portrayed here aim for the best responsiveness for finished work with the highest throughput. Throughput is measured in projects done. The companies increase their financial throughput by improving their operational throughput — for instance, by delivering new features or by providing a project result to a client.
- The companies bundle their work into projects. Indeed, there is 'daily work' for each team, but every larger batch of work (maintenance, changes, updates, features) is described as a project that is 'funneled' through the 'delivery process'.
- The size of a project — measured in the effort needed — is unknown upfront and may vary substantially.
- We can roughly know the dependencies between the teams for a multi-team project before starting.
- The principles and practices described aim for high throughput and low Flow Times per project — meaning doing things right (efficiency). That does not say anything about whether or not the things that are done so quickly are worth being done at all — meaning doing the right things (effectiveness). There are other principles and practices out there to find out what needs to be done in the first place. However, being fast supports fast learning and thus helps find out the right thing more quickly.
- The teams don't create plans. They have forecasts based on historical data (see the Flow Time Scatterplots).
- The teams have the authority to defer their commitment to the latest responsible moment. The commitment is not done 'for the teams' from stakeholders or formally authorized managers.
- The decision to 'pull' a project — meaning to start working on it — is made solely by the teams doing the work.
- The function of formally authorized management is to create an organizational structure that supports the flow of work and value creation. It's not the management's function to decide who has to start new work when.
- Although it's possible to constantly re-prioritize the upcoming but not started projects, the teams in this blog post sort the projects' First-in-First-out' (FiFo) while killing project ideas that have not been started for some time.
More sources
- Accelerate Your Enterprise Business Agility Journey — an excellent video on how to make your portfolio flow by Sally Elatta
- Actionable Agile Metrics for Predictability by Daniel Vacanti
- Agile Team's FAQ
- Covid-19 Makes Full Kitting In Business Processes A Critical Success Factor by Jonathan Sapir
- Delivering sooner by starting later — A counter-intuitive approach to product delivery 🚚 📦
- Full Kitting — Lean SCM by Joao Paulo Pinto
- Full Kitting Your Tasks by Martin Sweeny
- Hyper-Productive Knowledge Work Performance: The Tameflow Approach and Its Application to Scrum and Kanban (The Tameflow Hyper-productivity) by Steve Tendon and Wolfram Muller
- In jedem Unternehmen steckt ein besseres: Zeitorientierte Betriebswirtschaft mit dem Weichselbaum-System by Ernst Weichselbaum (in German only)
- Kanban Metrics by Gerard Chiva
- Lean Principle #4 — Defer Commitment by Kelly Waters
- Making Work Visible: Exposing Time Theft to Optimize Work & Flow by Dominica Degrandis
- Replacing Cycle Time with Flow Time by Steve Tendon
- Simulating the negative consequences of multitasking on flow, throughput, and value generation
- Starting late — The Superior Scheduling Approach
- Tame your Work Flow: How Dr. Goldratt of "The Goal" would apply the Theory of Constraints to rethink knowledge-work management (TameFlow) by Steve Tendon
- Theory of Constraints Drum Buffer Rope (DBR) by Lisa Lang
- Theory of Constraints on Wikipedia
- Theory of Constraints 101: Table of Contents by Tiago Forte
- Theory of Constraints 105: Drum-Buffer-Rope at Microsoft by Tiago Forte
- The Excellent Chain — The Full Kitting by GROUPE PSA
- The Goal: A Process of Ongoing Improvement by Eliyahu M. Goldratt and Jeff Cox
- The flow-centered retrospective — Learn to make your team flow
- The malicious behavior of non-constraints
- The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win by Gene Kim, Kevin Behr, and George Spafford
- The Positive Influence of Slack Time by Ivana Sarandeska
- The Pull Principle — In Production, the Office & in Life by MudaMasters
- Why We Need WIP Limits by Rachaelle Lynn
Understanding the simulation
Feel free to play around with the simulation by yourself. The whole simulation is open source to dive deep into the code and logic. To understand better what the simulation does, read on.
The simulation consists of two types of 'agents' with a particular behavior: Teams and Work Items (projects) to keep it simple and understandable. The simulation runs on workdays, and every simulation step is a workday, and we ignore weekends and holidays.

The Teams
The teams have two states. Each team may be working or not. Why a team is not working does not matter in the sense of the simulation — imagine a team event or a majority of the team members being on sick leave.
If a team is working is randomly determined with a probability of 5% — if dynamic is activated. Having a team not working about 12 days a 250 workday-year sounds reasonable.
Each team has a base capacity of eight people spending five dedicated work hours per workday on project work if projects are in process. On simulation start, the base capacity may be reduced by to up to 40% with a probability of 50% — because some teams are not as productive as others.
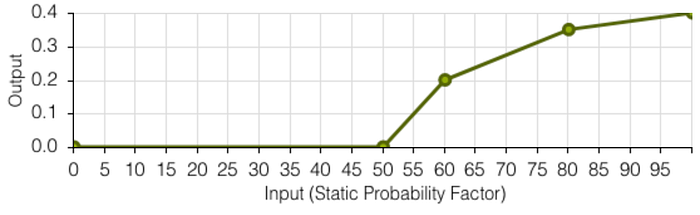
Moreover, every workday, each team's actual effort on projects may be reduced by up to 100%. Consider this a daily performance fluctuation that is common even among the best teams out there.

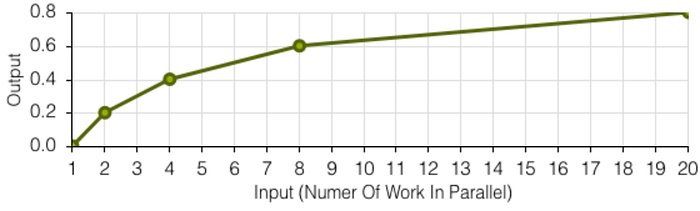
Of course, the number of projects that a team is working on simultaneously also affects the teams' available capacity to work on projects. Not only is the available capacity evenly spread between all the projects on the teams' plate, but multitasking also pays its toll. The more projects a team juggles, the lower the capacity available becomes. I assume that the 'price' for more than five projects in parallel is 50% of the available capacity. If this may sound extreme to you, I can tell you that you would be shocked how much effort goes into 'juggling' projects instead of finishing them — I even think that my capacity reduction factors are optimistic.
The Projects
Projects spawn randomly — not every workday generates project ideas, and some have more than one. Each project needs specific teams to be completed — this is known when the project comes into existence. I understand that this might contradict reality where we surprisingly discover that other teams than we expected need to be involved, but I had to make some assumptions here. One is that we know reasonably well which teams might be affected. Some projects may be done by a single team independently, and some need up to six teams (in this blog post, the maximum number of teams was five).
Every project starts as a 'new' project and has certain states over the entirety of its life.
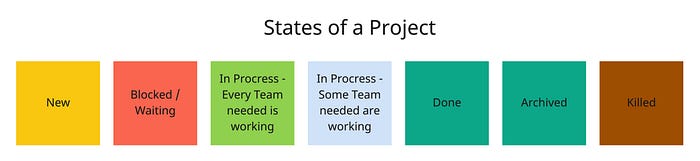
Whenever teams that are supposed to work on a project are in the state 'not working', the project gets blocked. If every team needed is working on the project, we consider the project 'in Process'. That does not mean that the full attention of every team lies on this particular project, and it just means that teams are 'juggling' the project on this specific workday. If not all the necessary teams are working on that project, we still consider the project 'in Process', but the simulation highlights those projects to see whether the teams' attention is on the project or not. If the whole effort needed to finish a project is 'delivered', the project is 'Done' and will be archived to keep the simulation tidy.
We think of projects that are not worked on 'Project Ideas'. After 100 workdays, an idea is considered too old to start. Those old ideas will be 'Killed'.
To make the simulation applicable to most contexts, we ignore each project's content and aim. We assume that every project has a scope that can be defined in total effort per team. This full effort is determined randomly for each project that spawns, and it's unknown for the teams doing the work — it's just 'known' by the simulation to determine if all the necessary work is done.
Every project starts with an effort per team involved, and this effort is determined by a base effort and an effort multiplier. I've tried to mimic reality in which, for some projects, some teams may be involved heavily but not in others.
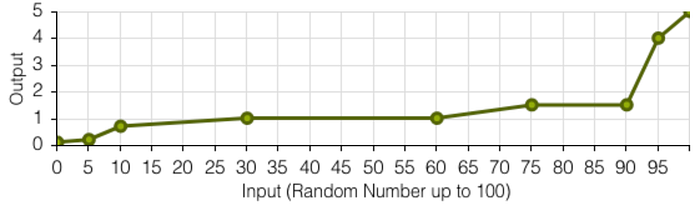
Each team's available per day capacity is subtracted from the total effort needed on every workday.
Again inspired by reality, the project scope may increase while running. That happens as soon as not all the involved teams work on that particular project. This inattention to the project results in rework, loads of questions to be answered, and synchronizations, increasing total effort whenever teams don't pay attention to a project in process—the scope increases by 1% per workday per team.
The Parameters
Since this blog post is all about Full Kitting, you may want to 'enforce' Full Kitting or not.
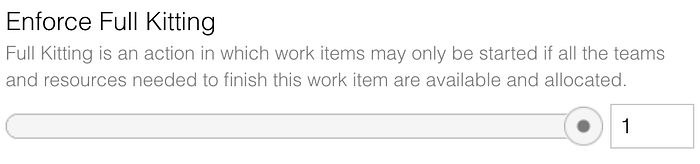
As we've seen, limiting the number of projects in process per team is super powerful. You may want to play around with the global per team WIP limit.

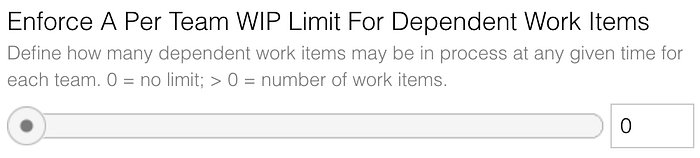
If the global per team WIP limit is larger than one, you may want to limit the number of projects having a dependency.
You may also want to define the number of teams in a given company — at a maximum of 20. The maximum number of dependencies per project is six.

The simulation does not put so much emphasis on prioritization. This is mainly because the need for prioritization is a sign of a delivery flow being neither smooth nor reliable. However, influencing if teams may foster working on multi-team projects or not seemed worthwhile to me. The base prioritization nevertheless is FiFo.

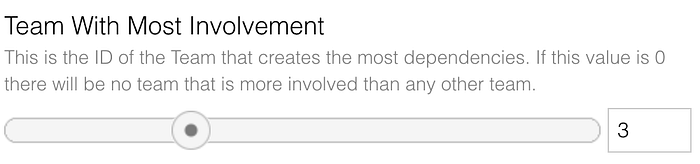
To simulate a company with a capacity constraint, we may enter a team ID that will be involved more frequently than others. Think about a platform team involved in feature development for many teams or a delivery team in a legacy environment. Having this team ID defined increases the odds of being involved in a multi-team project.
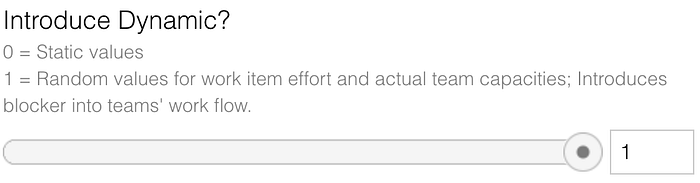
I've tried coming close to reality. Thus, I've introduced a lot of randomness into the simulation. I know that this does not mimic the ugly truth of genuine surprises in a complex world, but it gets close enough to the uncertainties in everyday company work. However, it can be hard to see the differences caused by the applied parameters when there is so much randomness. That's why you can safely remove all the randomness with just a slider.
Last but not least, you can change the goal of the simulation to come as close as possible to your context. You either burn down a scope of 30 projects in the shortest possible time or improve the overall Flow Times and the reliability of your teams by having an 'infinite' run simulating a 2.000 workday period.
Feel free to get in touch if you want to understand or use the simulation.
